Below, we show a list of selected publications and talks on the current research focus.
For the complete lists of papers, see Preprints, Conference Papers, and Journal Papers.
Research Focus
Theory and algorithms for deep learning with foundation models. 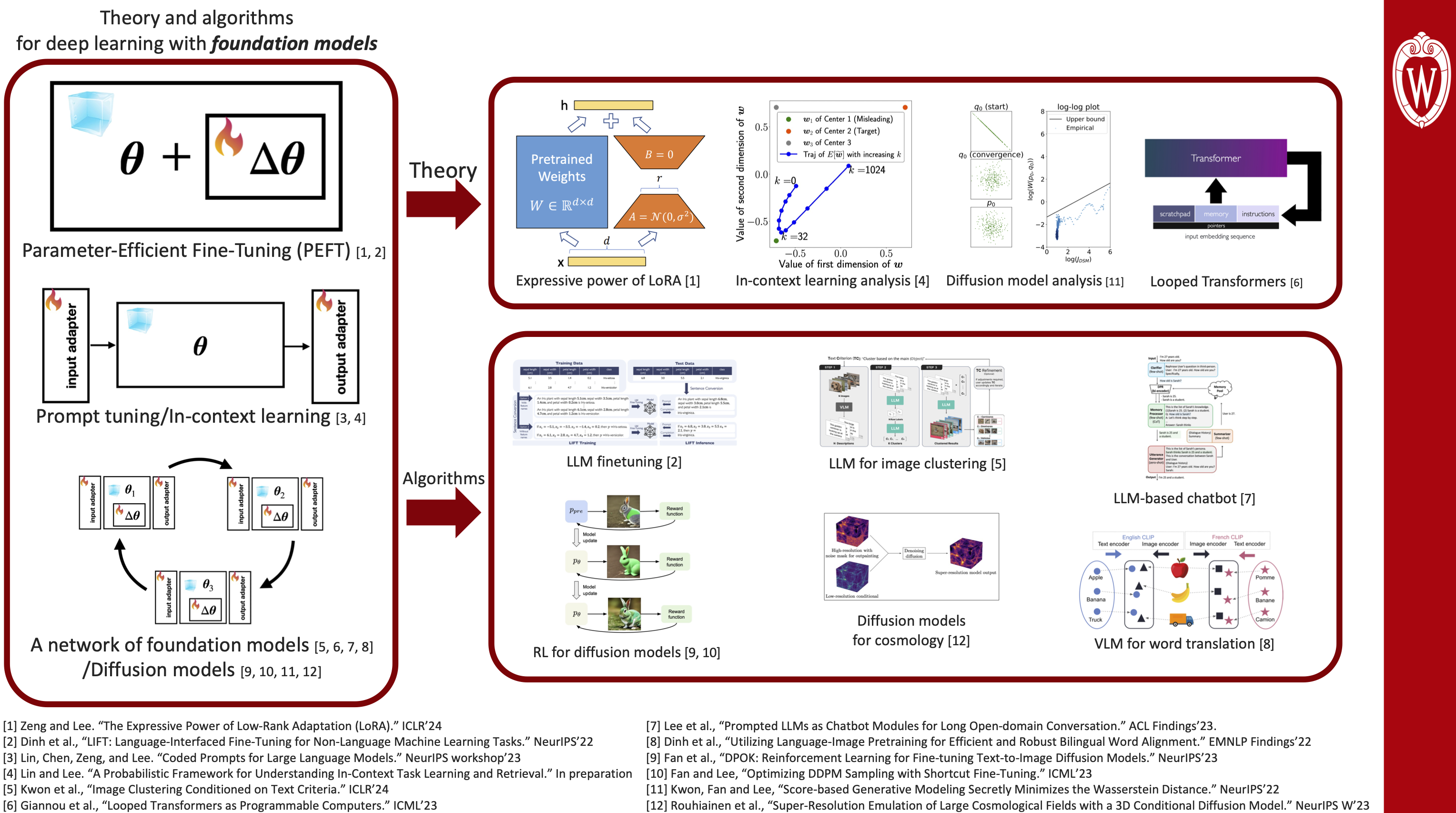
| Link | Topic/Type | TLDR | Summary | Github |
|---|---|---|---|---|
| Arxiv’24 | LLM/Theory | Dual Operating Modes of In-Context Learning | Summary | Github |
| Arxiv’24 | LLM/Algorithm | Can MLLMs Perform Text-to-Image In-Context Learning? | Summary | Github |
| ICLR’24 | PEFT/Theory | The Expressive Power of Low-Rank Adaptation (LoRA) | Summary | Github |
| ICLR’24 | LLM/Algorithm | Image Clustering Conditioned on Text Criteria | Summary | Github |
| ICLR’24 | LLM/Algorithm | Teaching arithmetic to a small Transformer | Summary | Github |
| ICLR’24 | LLM/Algorithm | A Looped-Transformer Architecture for Efficient Meta-learning | Summary | Github |
| NeurIPSW’23 | LLM/Algorithm | Coded Prompts for Large Language Models | ||
| NeurIPSW’23 | CLIP/Algorithm | Zero-shot Improvement of Object Counting with CLIP | ||
| NeurIPSW’23 | Diffusion/Algorithm | Super-Resolution Emulation of Large Cosmological Fields with a 3D Conditional Diffusion Model | ||
| NeurIPS’23 | Diffusion/Algorithm | Reinforcement learning for improved text-to-image alignment | Summary | Github |
| ICML’23 | LLM/Theory | Looped Transformers as Programmable Computers | Summary | Github |
| ICML’23 | Diffusion/Algorithm | Reinforcement learning for faster DDPM sampling | Summary | Github |
| ACL’23 (Findings) | LLM/Algorithm | An LLM agent with memory for long-term conversation | Summary | Github |
| EMNLP’22 (Findings) | LLM/Algorithm | Unsupervised word translation (via connecting two CLIP models) | Summary | Github |
| NeurIPS’22 | LLM/Algorithm | LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks | Summary | Github |
| NeurIPS’22 | Diffusion/Theory | Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance | Summary | Github |
| ICMLW’23 | CLIP/Theory | Mini-Batch Optimization of Contrastive Loss | Github | |
| TMLR | LLM/Algorithm | A compute-latency trade-off for language model decoding | ||
| ACLW’22 | LLM/Algorithm | Debiasing language models via parameter-efficient fine-tuning |
Selected Invited Talks on Deep Learning with Foundation Models
- (Dec. 2023) CSP Seminar @ University of Michigan
Title: Towards a Theoretical Understanding of Parameter-Efficient Fine-Tuning (and Beyond) - (Nov. 2023) Efficient ML workshop @ Google Research New York
Title: The Expressive Power of Low-Rank Adaptation (LoRA) - (Oct. 2023) Trust Perspectives in Machine Learning, Law, and Public Policy at the Institute for Data, Econometrics, Algorithms, and Learning (IDEAL) @ Northwestern University (Oct. 2023)
- (Oct. 2023) AI in Imaging and Medicine: Breaking Silos, Building Bridges @ University of Wisconsin-Madison
- (Sep. 2023) The Machine Learning for Medical Imaging (ML4MI) @ University of Wisconsin-Madison
- (May 2023) KSEA Distinguished Guest Series
- (Feb. 2023) Information Theory and Applications Workshop
- (Feb. 2023) The Coordinated Science Laboratory Student Conference @ UIUC
- (Jan. 2023) Information Theory and Data Science Workshop @ National University of Singapore
- (Jan. 2023) Systems, Information, Learning and Optimization (SILO) Seminar @ University of Wisconsin-Madison
- (Aug. 2022) Samsung Advanced Institute of Technology